PHP序列化的四种实现方法与横向对比教程(2)
二、PHP四种序列化方案横向对比
数据的序列化是一个非常有用的功能,然而目测很多人跟我一样,在刚接触这玩意的时候压根就不理解这货色到底是干啥用的,反正老师说了,实在理解不了就先背过再说。
其实将数据序列化的作用无外乎有两个:
- 方便传输
- 方便存储
方便存储如何理解呢?比如我们有个PHP对象或者一个PHP数组需要存储到数据库甚至文件中,这显然是不可能的,这个时候必须要将PHP对象或者PHP数组序列化后再执行存储操作。不过这将PHP数组序列化后存起来还能理解,这对象也能存储啊?这操作是否过于风骚?少年,这一点儿都不风骚。有些时候将对象直接存储起来,用的时候只需要简单的反序列化后就可以投产使用了,避免了new一次带来的性能耗费。
方便传输如何理解呢?其实序列化在传输中应用的相对更多更常见些许。最简单的一个例子,一个码前端的码了一个ajax找你给TA提供一个API,那么这个时候你俩得商量返回什么数据,比如json或者xml,甚至你俩自己作死约定私有数据格式。比如在一个比较典型的服务架构中,网关服务器和内部RPC服务器之间通过msgpack传递数据。这都是典型的序列化为了传输的典型应用案例。
这里序列化的概念可能更为广泛和笼统一些,包括传统的serialize、json、msgpack、protobuf等。( 如果你觉得序列化这个称呼不太严谨的话,可以用encode来代替;反序列化则用decode来代替。反正我就用统统用序列化和反序列化来称呼了,如果你觉得实在不舒服,可以顺着网线来砍我!)。
实际上,从更高的层面看,数据的序列化可以分为两种:
- 文本序列化,常见如json、serialize、xml等
- 二进制序列化,常见如msgpack、protobuf、thrift等
一般说来,考验序列化技术的性能指标一共有两个,一个是序列化的速度,一个是序列化后数据的大小,自然是序列化速度越快、序列化后的数据越小为佳。就目前来看,protobuf、msgpack等二进制序列化无论是速度上还是数据大小上,都要比文本序列化更好。不过话说回来,文本序列化有更好的可读性,一眼就能瞪出来数据内容大概是啥玩意。
今天带到这里的这里的有四个具体的方案,这四种方案都是简单粗暴、开箱即用类型的,我们分别测试感受下,看哪个更适合我们。
参会的四个哥们:PHP内置的serialize、PHP内置的JSON解析器、PHP扩展JSOND、PHP扩展msgpack。其中前三个都是文本类型的,msgpack则是二进制类型的。
JSOND作为PHP内置的JSON解析器的高级版本,坊间一直传闻速度上要比内置的更牛X一些,作为扩展,这货需要额外安装,附送地址:https://pecl.php.net/get/jsond-1.4.0.tgz。
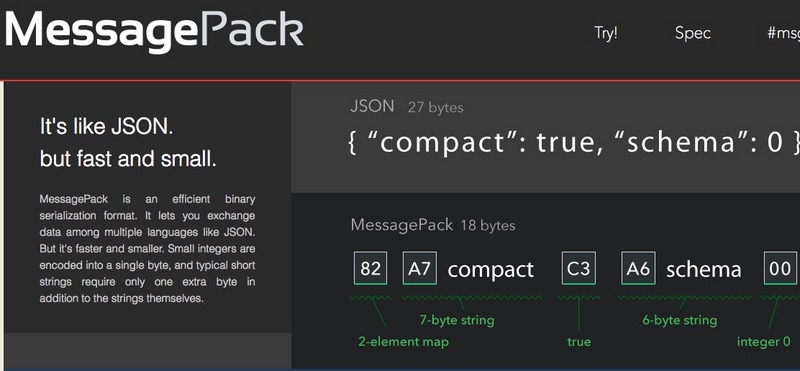
msgpack是一个鸟哥等人搞的一套二进制序列化工具,slogan就是“It's like JSON.but fast and small.”,附送地址:https://pecl.php.net/get/msgpack-2.0.2.tgz
1、serialize用法
serialize(),序列化方法。
unserialize(),反序列化方法。
2、json用法
json_encode(),没啥好说的吧?
json_decode(),没啥好说的吧?
3、jsond用法
jsond_encode(),和json_encode()一样,后面多个字母d而已。
jsond_decode(),和json_decode()一样,后面多个字母d而已。
4、msgpack用法
msgpack_pack(),序列化方法。
msgpack_unpack(),反序列化方法。
测试代码如下:
<?php// 故意搞了一个还算大的php数组,更容易看出差距来$arr=array(array('uid'=> 22193123,'gender'=>'famale','username'=>'elarity','password'=> md5('www123'),'relation'=>array(array('uid'=> 22193123,'gender'=>'famale','username'=>'elarity','password'=> md5('www123'),),array('uid'=> 22193123,'gender'=>'famale','username'=>'elarity','password'=> md5('www123'),),array('uid'=> 22193123,'gender'=>'famale','username'=>'elarity','password'=> md5('www123'),),array('uid'=> 22193123,'gender'=>'famale','username'=>'elarity','password'=> md5('www123'),),array('uid'=> 22193123,'gender'=>'famale','username'=>'elarity','password'=> md5('www123'),),array('uid'=> 22193123,'gender'=>'famale','username'=>'elarity','password'=> md5('www123'),),array('uid'=> 22193123,'gender'=>'famale','username'=>'elarity','password'=> md5('www123'),),array('uid'=> 22193123,'gender'=>'famale','username'=>'elarity','password'=> md5('www123'),),array('uid'=> 22193123,'gender'=>'famale','username'=>'elarity','password'=> md5('www123'),),),));// 每种序列化方案都执行100000次$counter= 100000;// json序列化方案,执行100000次echoPHP_EOL.PHP_EOL;$start= microtime( true );for($i= 1;$i<=$counter;$i++ ){$json= json_encode($arr);}$size=strlen($json);$end= microtime( true );$cost_time=$end-$start;echo"json_encode : 耗费时间为{$cost_time} , 数据体积为{$size}".PHP_EOL;// jsond序列化方案,执行100000次$start= microtime( true );for($i= 1;$i<=$counter;$i++ ){$jsond= jsond_encode($arr);}$size=strlen($jsond);$end= microtime( true );$cost_time=$end-$start;echo"jsond_encode : 耗费时间为{$cost_time} , 数据体积为{$size}".PHP_EOL;// serialize序列化方案,执行100000次$start= microtime( true );for($i= 1;$i<=$counter;$i++ ){$serialize= serialize($arr);}$size=strlen($serialize);$end= microtime( true );$cost_time=$end-$start;echo"serialize : 耗费时间为{$cost_time} , 数据体积为{$size}".PHP_EOL;// msgpack序列化方案,执行100000次$start= microtime( true );for($i= 1;$i<=$counter;$i++ ){$msgpack= msgpack_pack($arr);}$size=strlen($msgpack);$end= microtime( true );$cost_time=$end-$start;echo"msgpack耗费时间为 : {$cost_time} , 数据体积为{$size}".PHP_EOL;echoPHP_EOL.PHP_EOL;
将文件保存为test.php,然后php test.php执行,结果如下图所示:
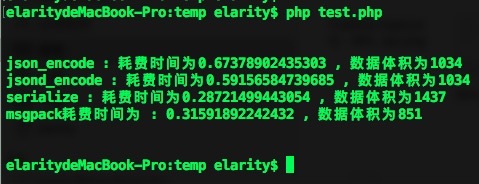
总结一下:
- jsond确实是要比json快一些的
- 总有刁民张嘴就来json要比serialize()快
- serialize()数据体积确实大(因为还保留了数据类型说明)
- msgpack最佳???不知道昂,你们自己感受




